
从神秘的汇编代码到C语言的main()函数,这中间发生了什么?为什么我们的全局变量能够正常使用?为什么中断服务程序能够准确响应?这一切的答案,都隐藏在那个常常被我们忽略的启动文件中。
在嵌入式开发中,我们往往专注于业务逻辑的实现,却很少深入思考:当芯片上电复位的那一刻,硬件是如何一步步搭建起C语言的运行环境的?今天,就让我们一同揭开STM32启动文件的神秘面纱,探寻从硬件到软件的桥梁是如何搭建的。
本系列文章将从内存管理的角度出发,基于Cortex-M3内核的启动文件进行深度解析。建议读者打开任意一个STM32F103工程的启动文件(通常命名为startup_stm32f103xb.s),跟随本文的脚步,一起探索。
在启动文件之初,首先会通过汇编指令为堆区(Heap)和栈区(Stack)分配内存空间,这也是搭建C语言运行环境的关键步骤,具体代码如下所示:
Stack_Size EQU 0x400
AREA STACK, NOINIT, READWRITE, ALIGN=3
Stack_Mem SPACE Stack_Size
__initial_sp
; <h> Heap Configuration
; <o> Heap Size (in Bytes) <0x0-0xFFFFFFFF:8>
; </h>
Heap_Size EQU 0x200
AREA HEAP, NOINIT, READWRITE, ALIGN=3
__heap_base
Heap_Mem SPACE Heap_Size
__heap_limitStack_Size定义了栈区的大小,通过EQU 0x400将其设置为 1024 字节(1KB)Heap_Size同样使用EQU指令,为堆区分配了 512 字节的空间
在这里就会为大家抛出一个疑问:什么是堆和栈?它们在嵌入式系统中扮演着什么角色?
简单来说,堆和栈都是位于 STM32 RAM(随机存取存储器) 中的内存区域。RAM 具有可读可写的特性,通常用于存储程序运行过程中产生的临时数据,这些数据在断电后会丢失。除了堆和栈之外,RAM 中还包含 .data 段和 .bss 段,它们共同构成了程序的运行时内存布局:
- 堆(Heap):用于动态内存分配,程序员可以通过
malloc、free等函数主动申请和释放内存空间。 - 栈(Stack):主要用于存储函数调用时的局部变量、函数参数和返回地址等临时数据。
- .data段:已初始化的全局/静态变量。
.bss段:未初始化的全局/静态变量。
了解了 RAM 的用途,我们再来看看 STM32 的另一个重要存储介质——ROM(只读存储器),也就是我们常说的 Flash。与 RAM 不同,Flash 中存储的数据具有掉电不丢失的特性,因此我们编译好的程序代码就是存储在 Flash 中的(想象一下如果程序存储在 RAM 中,每次重新上电都需要重新烧录,那将是多么可怕的场景哈哈)。Flash 主要包含以下段:
.text段:存储程序代码的可执行代码。.rodata段:常量字符串、const常量,具有只读属性(从这个角度来看我们也就可以知道为什么const修饰的变量我们不能修改了,因为他存储在ROM只读区)。
理解了这些基础知识后,我们再回头看启动文件中的配置,就能发现以下代码在当前工程设置下是存在问题的:
void function1() {
char buf[2048]; // 栈溢出!(栈只有1KB),而此处声明了2KB。
}
void function2() {
char *buf = malloc(1024); // 堆空间不足!堆空间在启动文件中只是分配了512个字节
}看到启动文件为我们分配的堆栈资源如此有限,很多开发者可能会产生疑问:在面对需要大量内存的应用场景时(比如处理HTTP协议、图像处理、复杂通信协议等),我们是否就束手无策了呢?当然不是! 关键在于我们要主动管理和优化内存资源。
首先,让我们探查STM32芯片中可用的RAM资源。点击Keil的”魔术棒”(Options for Target),在Target选项卡中可以看到内存配置:
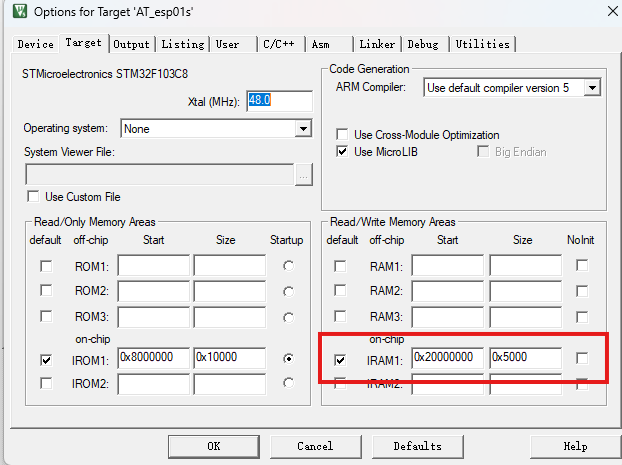
- RAM起始地址: 0x20000000
- 大小: 0x5000 (20KB)
这意味着我们的芯片拥有20KB的RAM资源!大概的布局就是这样的。

而系统只给我们分配了1KB的堆和0.5KB的栈,可以见得是不是太小气了点哈哈。
看到这个配置,你可能会想:20 - 1 - 0.5 = 18.5KB,这不是还有大量空闲RAM吗?且慢!别忘记了之前提及的RAM资源可不只有堆区和栈区,还有一个重要的”内存消耗者”——全局变量。
在嵌入式系统中,RAM不仅要为堆栈服务,还要存储程序中所有的全局变量和静态变量。这些变量的内存占用不会在启动文件中体现,而是在编译后自动确定。幸运的是,Keil在编译后会生成一个.map文件(直接在工程目录下搜.map即可找到),这个文件就像我们的”内存账本”,详细记录了每一字节内存的去向。查看其中的关键数据:
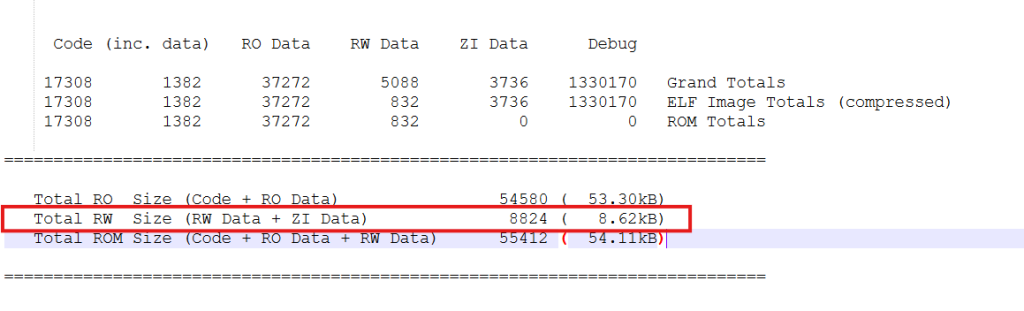
可见我们的全局变量用了大概8.62KB的RAM,所以我们真实结余的RAM空间是20-1-0.5-8.62=9.88KB!既然发现了这9.88KB的可利用空间,我们就可以根据应用需求,智能地重新分配堆栈比例。比如,对于一个需要处理网络数据的应用:
Stack_Size EQU 0x1000 ; 栈: 4KB (原来1KB)
Heap_Size EQU 0x0800 ; 堆: 2KB (原来0.5KB)现在的RAM使用情况就是20-4-2-9.88=4.12KB(合理预留!)
在深入理解启动文件之前,博主也曾在堆栈资源的困扰中挣扎——栈溢出导致的数据踩踏、堆空间不足造成的内存分配失败,这些内存问题屡屡导致程序崩溃。过去的解决思路往往局限于”节流”:削减缓冲区大小、简化数据结构、甚至牺牲功能特性。这种方法虽然能暂时缓解问题,但本质上治标不治本,既费时费力,又限制了系统的扩展性。
通过今天介绍的主动内存管理方法,我们完全可以换一种思路:基于准确的内存使用数据,对RAM资源进行科学的架构设计。这种”开源”而非”节流”的思维转变,让我们能够在有限的硬件资源内实现最优的性能配置。
说到这里,不得不提连接整个内存体系的关键一环——分散加载文件(.sct文件)。这个由Keil根据工程配置自动生成的文件,实际上定义了程序的内存布局蓝图(我们同样可以在项目目录下搜索.sct文件)。
; *************************************************************
; *** Scatter-Loading Description File generated by uVision ***
; *************************************************************
LR_IROM1 0x08000000 0x00010000 { ; 加载区域:Flash 64KB
ER_IROM1 0x08000000 0x00010000 { ; 执行区域:代码和常量
*.o (RESET, +First) ; 中断向量表优先放置
*(InRoot$$Sections) ; 库的初始化段
.ANY (+RO) ; 所有只读数据
}
RW_IRAM1 0x20000000 0x00005000 { ; 执行区域:RAM 20KB
.ANY (+RW +ZI) ; 所有读写和零初始化数据
}
}
.sct文件与启动文件形成了完美的分工协作:
- .sct文件:在编译链接阶段划定内存边界
- 启动文件:在运行阶段,在边界内划分堆栈
理解了这三者的关系(Keil配置 → .sct文件 → 启动文件),我们就建立起了从源码到硬件的完整认知链条。下次面对内存挑战时,你将拥有从架构层面解决问题的底气与能力!
打卡
😊
hhhh
点我
感谢分享
希望可以帮到你!
点我